Penerjemah Resmi
by Translation Transfer

Penerjemah Resmi
by Translation Transfer
Penerjemah Resmi
by Translation Transfer
Penulis: Moch Andike Arifin Ilham

Natural Language Processing | Definisi dan 5 Kekurangannya – Mungkin kata Natural Language Processing masih terdengar cukup asing di telinga kita. Di era yang serba digital seperti sekarang ini, penggunakan Artificial Intelligence (AI) seperti Natural Language Processing sangat marak dan lumrah digunakan dalam kehidupan sehari-hari. Hal ini juga digunakan sebagai alternatif untuk mempermudah kegiatan manusia semakin lebih cepat, efisien, dan produktif.
Natural Language Processing atau biasa disingkat sebagai NLP adalah cabang dari kecerdasan buatan (AI) yang diciptakan dengan tujuan agar komputer dapat memahami, menganalisis, serta memproses bahasa manusia secara alami.
Sederhananya, NLP merupakan mesin yang digunakan untuk berkomunikasi antara bahasa manusia baik teks maupun ucapan dengan bahasa pemrograman yang lebih terstruktur. NLP dapat melakukan analisis dan menafsirkan perintah, menghasilkan informasi penting dari teks, bahkan merekonstruksi ulang bahasa yang dapat menyerupai bahasa manusia saat berbicara atau menulis.
Secara harfiah Natural Language Processing adalah piranti perangkat lunak yang disematkan ke dalam perangkat keras seperti gawai dan laptop. Hal ini memang benar adanya karena NLP sendiri adalah cabang dari kecerdasan buatan berbentuk perangkat lunak berupa sistem. Namun, teknologi NLP ini dapat diwujudkan dalam bentuk aplikasi seperti asisten virtual, penerjemahan otomatis, analisis teks, dan masih banyak lagi bentuk adaptasi NLP di dunia nyata.
Baca juga: Jasa Interpreter Bali | 100% Resmi dan Bertanggungjawab
Sejarah Natural Language Processing dimulai sejak perkembangan awal kecerdasan buatan (AI). Semenjak pertengahan abad ke-20, penelitian di bidang ini telah mengalami berbagai fase dan berkembang seiring berjalannya waktu dan kemajuan teknologi. Berikut merupakan garis waktu perkembangan sejarah NLP:
Di era ini, fokus utamanya adalah pada gagasan dasar tentang “apakah mesin dapat berpikir dan memahami bahasa manusia”. Salah satu pencapaian penting adalah “Tes Turing“ yang diusulkan oleh Alan Turing pada tahun 1950. Tes ini dirancang untuk mengukur kemampuan mesin dalam menunjukkan perilaku cerdas yang tak dapat dibedakan dari manusia dalam percakapan berbasis teks.
Pada 1960-an, pendekatan berbasis aturan mendominasi penelitian NLP. Salah satu sistem awal yang terkenal adalah ELIZA (1966), sebuah program yang meniru percakapan terapeutik dengan manusia menggunakan pola dan aturan yang telah ditentukan sebelumnya. ELIZA menunjukkan bagaimana komputer dapat “berbicara” dengan manusia, meskipun terbatas pada pola sederhana.

Di tahun 1970-an, fokus NLP mulai bergeser ke penerapan nyata, termasuk sistem penerjemahan mesin dan pencarian informasi. Salah satu proyek penting adalah program SHRDLU yang dirilis pada tahun 1968 serta mampu memahami dan menjalankan perintah dalam bahasa alami untuk memanipulasi objek di lingkungan virtual sederhana. Namun, model berbasis aturan pada saat itu terbatas dalam skala dan rentan terhadap kegagalan ketika menangani bahasa yang lebih kompleks.
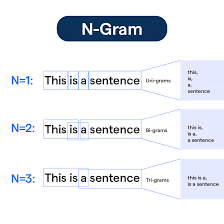
Pada 1980-an, pendekatan statistik mulai mendapatkan popularitas, menggantikan metode berbasis aturan yang kaku. N-gram models dan teknik statistik lainnya diperkenalkan untuk mengatasi masalah ketidakpastian dan ambiguitas dalam bahasa manusia. Dengan pendekatan ini, komputer tidak lagi hanya bergantung pada aturan yang telah ditentukan, melainkan menggunakan probabilitas untuk memahami konteks bahasa.
Kemajuan dalam pembelajaran mesin (machine learning) selama 1990-an membawa perubahan besar dalam NLP. Komputer mulai dilatih menggunakan data besar (big data) dan model statistik untuk mengenali pola-pola dalam bahasa. Teknik seperti Hidden Markov Models (HMM) dan Support Vector Machines (SVM) digunakan untuk tugas-tugas seperti pengenalan suara, tag POS (part-of-speech), dan analisis sintaksis. Di era ini juga muncul peningkatan dalam pencapaian sistem penerjemahan otomatis dan pengenalan suara.
Memasuki abad ke-21, perkembangan pesat dalam deep learning dan neural networks membawa revolusi dalam NLP. Salah satu terobosan utama adalah pengenalan model Word2Vec (2013) yang memungkinkan representasi kata sebagai vektor numerik yang menangkap makna semantik. Model ini membuka jalan bagi pendekatan modern dalam pemrosesan bahasa alami.

Pada akhir 2010-an, muncul model Transformer yang mengubah lanskap NLP secara dramatis. Model BERT (Bidirectional Encoder Representations from Transformers) yang diperkenalkan oleh Google pada tahun 2018 menjadi salah satu terobosan terbesar, memungkinkan komputer untuk memahami konteks bahasa dengan lebih baik dari sebelumnya. Model lain seperti GPT (Generative Pretrained Transformer) juga menjadi populer untuk menghasilkan teks yang menyerupai bahasa manusia.
Di tahun 2020-an, model NLP berskala besar seperti GPT-3 dan ChatGPT (Generative Pretrained Transformer) yang dikembangkan oleh OpenAI mampu menghasilkan teks yang sangat alami dan meniru percakapan manusia dengan akurasi yang mengesankan. Perkembangan ini membawa NLP ke dalam berbagai aplikasi praktis, mulai dari layanan customer service otomatis, penerjemahan, hingga alat bantu kreatif.
Sekarang, penggunaan NKP sangat gencar dikembangkan dan digunakan secara masif di era digital sehingga kegiatan manusia pun semakin dimudahkan oleh kehadiran kecerdesan buatan yang mampu meniru kualitas pembicaraan layaknya manusia pada umumnya. Namun, seiring pesatnya perkembangan teknologi tentunya tetap ada beberapa kekurangan yang ada dalam mesin NLP.
Baca juga: Jasa Subtitle | Solusi Terbaik Meningkatkan Subscriber Youtube
Bahasa manusia penuh dengan ambiguitas, baik secara leksikal (kata yang memiliki lebih dari satu makna) maupun sintaksis (struktur kalimat yang dapat diinterpretasikan dengan cara yang berbeda). Sebagai contoh sederhana pada kalimat “Dia melihat burung dengan teropong” dapat diartikan bahwa subjek ‘dia’ menggunakan teropong untuk melihat burung atau objek ‘burung’ itu sedang membawa teropong.
Meski model NLP modern mampu menangani beberapa ambiguitas dan keterbatasan dalam memahami konteks terutama konteks historis atau emosional dari percakapan yang panjang. NLP seringkali hanya berfokus pada urutan kata atau frasa terdekat, tetapi gagal dalam memahami konteks yang mencakup paragraf atau percakapan yang lebih panjang.
Bahasa manusia sering kali tidak terstruktur dengan baik, penuh dengan kesalahan ketik, penggunaan slang atau bahasa gaul, atau ungkapan idiomatik yang sulit dipahami oleh model NLP. Seringkali model NLP tidak dapat mengidentifikasi beberapa frasa yang tersusun tidak rapi sehingga hasil terjemahannya terlihat amburadul. Kebanyakan NLP hanya mampu menerjemahkan kata per kata tanpa bisa memahami konteks dari kata sebelum dan sesudahnya.
NLP modern belakangan ini telah menggunakan teknik pembelajaran deep learning yang membutuhkan jumlah data latih yang besar agar berfungsi secara efektif. Hal ini menciptakan tantangan besar untuk dapat memaksimalkan kinerja NLP itu sendiri.
Bahasa manusia memiliki keunikan tersendiri dibanding bahasa-bahasa lain yang ada di dunia. Bahasa manusia memiliki majas atau gaya bahasa yang berfungsi sebagai penghalus makna, nilai estetika ketika menulis dan berbicara atau sekadar sebagai gurauan belaka. NLP yang merupakan bahasa pemrograman komputer seringkali kesulitan dalam memahami ironi, sarkas, dan humor dari bahasa manusia sehingga menerjemahkannya secara literal tanpa pemahaman konteks yang benar.
Bahasa manusia terus berkembang, baik dari segi kosakata baru, tren bahasa, maupun perubahan makna kata. NLP memerlukan pembaruan secara terus-menerus agar tetap relevan dengan perubahan tren bahasa ini. Model yang dilatih di masa lalu mungkin gagal memahami istilah-istilah baru, atau tren bahasa, seperti bahasa gaul atau meme internet, yang tidak tercakup dalam data latihnya.

Sebagai manusia yang utuh serta dikaruniai akal oleh Tuhan, manusia mungkin bisa saja terkalahkan dominasi dan fungsinya oleh penggunaan kecerdasan buatan yang semakin masif dikembangkan. Namun, perlu diingat dari sekian banyak fungsi kecerdasan buatan pastinya terdapat kekurangan dalam pengaplikasiannya sehingga masih membutuhkan jasa manusia itu sendiri untuk mengatasinya.
Oleh sebab itu, meskipun pengaruh kecerdasan buatan penerjemahan dan robot sudah sangat melekat di dalam kehidupan manusia, peran penerjemah tersumpah manusia masih diperlukan guna sebagai koreksi hasil terjemahan yang dilakukan oleh robot. Robot memang dapat melakukan segala pekerjaan dalam satu waktu secara cepat dibandingkan manusia, tetapi bukan berarti robot tidak pernah melakukan kesalahan. Disinilah peran manusia terutama penerjemah tersumpah untuk melakukan tugasnya.












